C Getting to Know R
For solutions to various exercises involved in the class and for general computations performed in the lectures and throughout these notes, the statistical programming language R has been used. (R Core Team 2016) This programming environment (a) is available on all major platforms (Mac, PC, unix, linux), (b) has many easy-to-use (and many not-so-easy-to-use) built-in functions for plotting data, generating curves, manipulating matrices, etc., and best of all (c) is freely available for download over the internet.
After installing R (and, perhaps, Rstudio) on your system and initializing,
- in the Console window, type commands and hit Return:
34 + 17## [1] 51sqrt(49)## [1] 7besselI(0.25,1)## [1] 0.1259791pi## [1] 3.141593- in the Source window, select lines that you wish to execute and (a) hit Run, or (b) hit Command-Return (MAC) or Control-Return (PC)
- if have a text file located in a directory /dir/filename that contains R commands, can type
source("/dir/filename")(quotation marks must be included) in the console window and hit Return to execute the commands.
C.1 Doing Simple Calculations
Define variables and perform calculations…
E0 = 938; W = 8000
sqrt( 1 - (E0/(E0+W))^2 )## [1] 0.994478# or, define a variable:
beta = sqrt( 1 - (E0/(E0+W))^2 )
# just typing the name of the variable displays its value:
beta## [1] 0.994478Create a function as follows:
beta = function(x){ sqrt( 1 - (E0/(E0+x))^2 ) }
beta(8000)## [1] 0.994478Make a list of numbers and perform a calculation on all of them
x = c(0,2,5,9,23)
beta(x)## [1] 0.0000000 0.0651981 0.1028413 0.1375393 0.2174718Round off our answers to 3 digits
round(beta(x),3)## [1] 0.000 0.065 0.103 0.138 0.217C.2 Making Simple Plots
x = c(0,1,2,3,4,5,6,7,8,9)
y = beta(x)
plot(x,y)
Plot a curve of a function
curve(beta,0,10)
Plot the points, and add a curve to the same plot; also, add some new labels to the axes
plot(x,y,
xlab="proton kinetic energy [MeV]", ylab="v/c", main="Velocity vs. Kinetic Energy")
curve(beta, 0, 10, add=TRUE, col="blue")
C.3 Creating Random Distributions
# Uniform Distribution of Npts points between 0 and 1
Npts = 500
r = runif(Npts,0,1)
plot(r)
hist(r)
# Normal (Gaussian) Distribution of Npts points, with mean=0, sigma=sig
sig=2
set.seed(231) # set the random number seed to get same results each run
r = rnorm(Npts,0,sig)
plot(r)
hist(r)
curve(Npts/(sqrt(2*pi)*sig)*exp(-x^2/(2*sig^2)), add=TRUE, col="blue")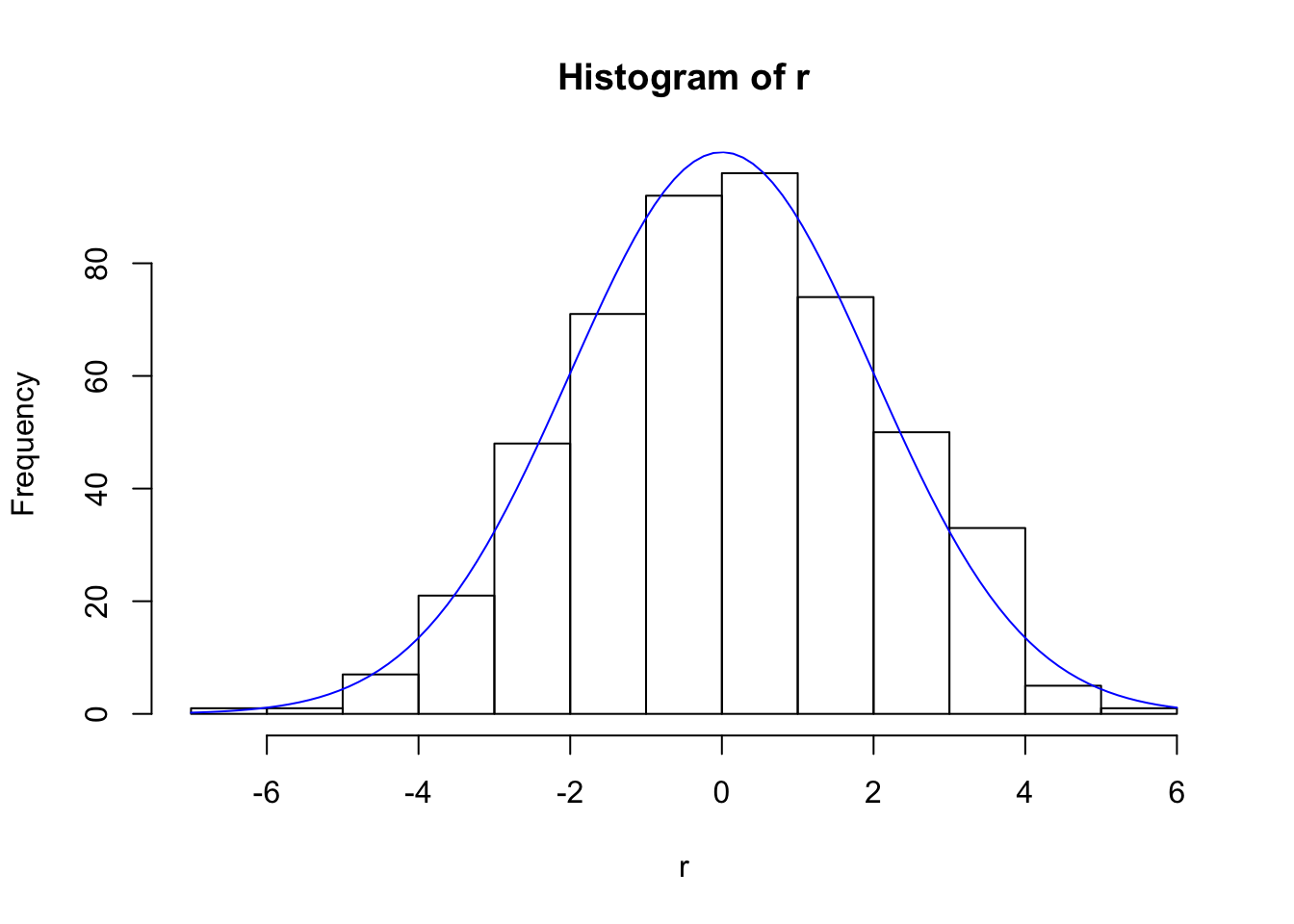
C.4 Decisions and Loops
imax=10
x = array(c(1:imax))
x## [1] 1 2 3 4 5 6 7 8 9 10i = 1
while (i<imax){
x[i+1] = x[i] + 12
i = i+1
}
x## [1] 1 13 25 37 49 61 73 85 97 109Can use ifelse(test,yes,no) to perform tests and make decisions
imax=10
x = runif(imax,-1,1)
round(x,2)## [1] -0.17 0.29 -0.56 0.82 -0.32 -0.25 -0.25 0.24 -0.70 0.50i = 1
while (i<imax+1){
x[i] = ifelse(x[i]<0, abs(x[i]), x[i])
i = i+1
}
round(x,2)## [1] 0.17 0.29 0.56 0.82 0.32 0.25 0.25 0.24 0.70 0.50C.5 Matrix Manipulations
A matrix is essentially an ordered list; so, create a list of numbers and tell R where to break the list into rows or columns.
M = matrix( c(1,2,3,4), ncol=2, byrow=TRUE)
M## [,1] [,2]
## [1,] 1 2
## [2,] 3 4Nice to type the input this way, to visually emphasize the arrangement:
A = matrix( c(1, 2,
3, 4 ), ncol=2, byrow=TRUE)
A## [,1] [,2]
## [1,] 1 2
## [2,] 3 4B = matrix( c(5, 6,
7, 8 ), ncol=2, byrow=TRUE)
B## [,1] [,2]
## [1,] 5 6
## [2,] 7 8Multiply matrices – but be careful! If you write A * B, this will take each element of A (say a11) and multiply by the corresponding element in B (say b11). What we want is a real matrix multiply – performed using the %*% operator:
C = A * B
C## [,1] [,2]
## [1,] 5 12
## [2,] 21 32WRONG!!
Here’s the right way (in R ):
C = A %*% B
C## [,1] [,2]
## [1,] 19 22
## [2,] 43 50Take the transpose using t(), determinant using det()
t(A)## [,1] [,2]
## [1,] 1 3
## [2,] 2 4det(A)## [1] -2To find the inverse of a matrix, we use the solve() function:
solve(A)## [,1] [,2]
## [1,] -2.0 1.0
## [2,] 1.5 -0.5Check:
A %*% solve(A)## [,1] [,2]
## [1,] 1 1.110223e-16
## [2,] 0 1.000000e+00solve(A) %*% A## [,1] [,2]
## [1,] 1 4.440892e-16
## [2,] 0 1.000000e+00The function solve(A,B) solves the equation \(A\vec{x} = B\) for \(\vec{x}\). If \(B\) is missing in the solve() command, it is taken to be the identity and the inverse of \(A\) is returned. If you don’t like all the extra digits above, try:
round(solve(A) %*% A, 10)## [,1] [,2]
## [1,] 1 0
## [2,] 0 1Multiply a vector by a matrix to get a new vector; still use the operator %*%…
x = c(2,1)
x## [1] 2 1t(t(x)) # trick, to see it in a "usual" (up/down) vector format## [,1]
## [1,] 2
## [2,] 1A## [,1] [,2]
## [1,] 1 2
## [2,] 3 4A %*% x## [,1]
## [1,] 4
## [2,] 10C.6 Reading/Writing Data
Write a set of numbers to a file, and read them back in…
x = runif(500,3,9)
y = rnorm(500,2,6)
write.table(cbind(x,y), file="data.txt")
data = read.table("data.txt")
head(data)## x y
## 1 8.405329 4.752421
## 2 8.990993 -6.413817
## 3 3.436147 2.626524
## 4 5.367637 7.377437
## 5 3.300938 1.870243
## 6 3.387021 -8.907860xx = data[[1]] # first column
yy = data[[2]] # second column
plot(xx,yy)
abline(h=c(mean(yy),mean(yy)+c(-1,1)*sd(yy)),
lty=c(1,2,2),lwd=2,col=c("red","blue","blue"))
abline(v=mean(xx),lty=1,lwd=2,col="green")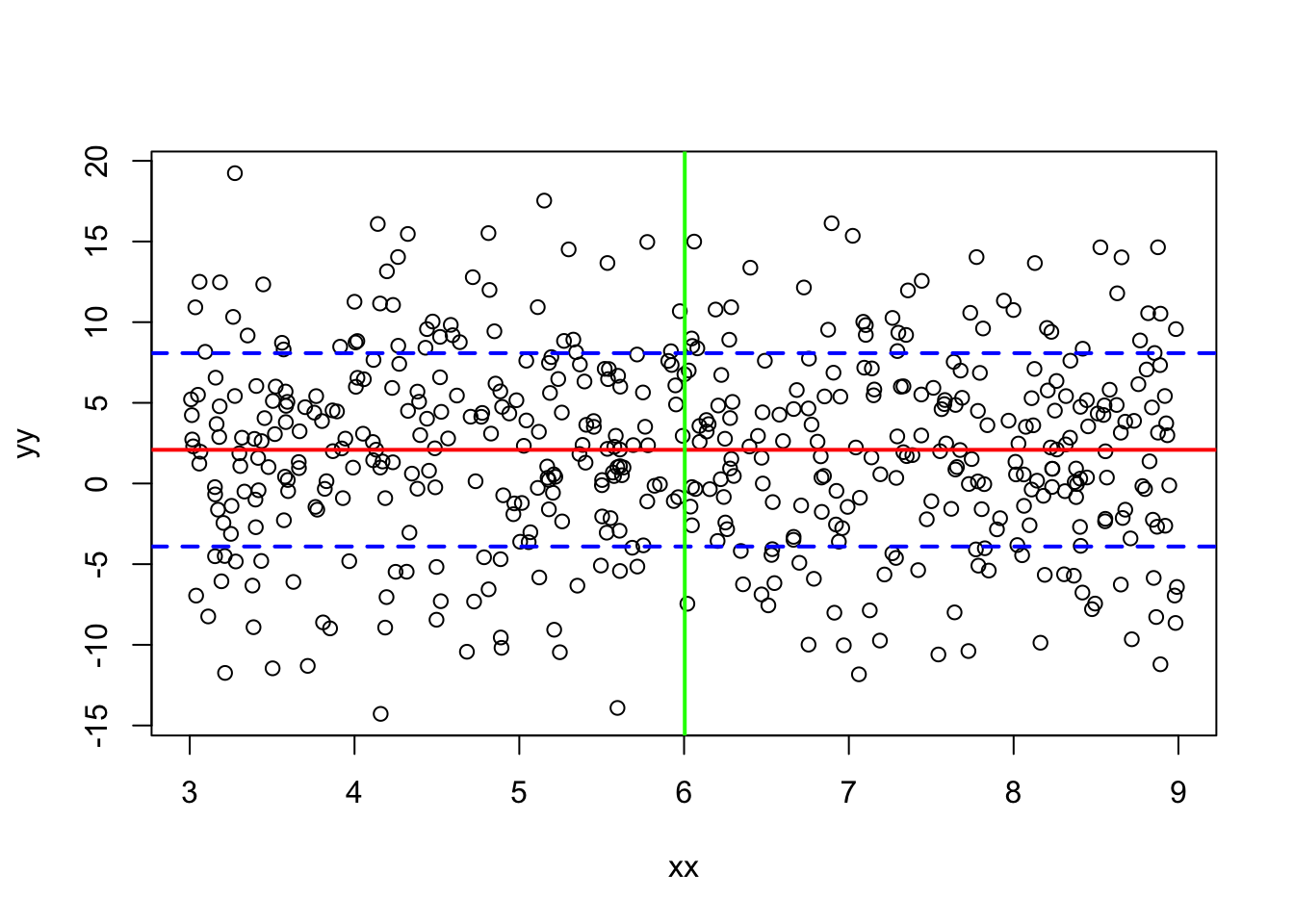
Note: The abline() function adds either horizontal, vertical, or general (\(y = a + bx\)) lines to an existing plot. The argument “typ” depicts the style of the line (solid, dotted, etc.).
C.7 Dataframes
Often times we wish to create or maybe read in a table of data, perhaps from measurements that were taken or from the results of a computer simulation, and take a quick look at the numbers, make simple plots, or pursue other manipulations. Above we read in data from a file and then identified new variables for each of the two columns of numbers. Below we will generate a new file of data and read it in using the read.table command; this will create a “dataframe” in R which makes many new options available for our use.
# Create some sample data and write to a file, with a header line
x = rnorm(50,0,2)
y = rnorm(50,0,5)
p = (y/5*2-5*x)/10
z = 2-(x+runif(50,-2,2))/2
filename = "data2.txt"
write(c("x","y","z","dp"), file=filename, ncol=4) # creates the file header
write(c(x,y,z,p), file=filename, ncol=4,append=TRUE) # writes the dataNext, we read the file back in, creating a dataframe named “data”.
filename = "data2.txt"
data = read.table(file=filename,header=TRUE,sep="")
# What have we created?
attributes(data)## $names
## [1] "x" "y" "z" "dp"
##
## $class
## [1] "data.frame"
##
## $row.names
## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
## [24] 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46
## [47] 47 48 49 50head(data) # look at first few lines of the dataframe## x y z dp
## 1 -1.4275730 -1.3736950 -1.3159790 1.7580210
## 2 -0.6537441 0.5998719 2.3382920 0.2171682
## 3 2.1875660 -0.5753788 -0.4642891 -2.8730000
## 4 -1.6811330 -0.7724082 -1.7751660 3.3139460
## 5 -0.3702498 0.7637552 -2.2209970 3.9664440
## 6 -2.0383670 -2.7025750 1.4797320 -2.1612550Note that the names of the columns in our dataframe are taken from the header (first line) of the text file we read in. To access the data for one of the variables (columns) from our dataframe data we use the dollar sign:
length(data$x) # number of entries for "x"## [1] 50data$x[23] # value of 23rd entry for "x"## [1] 3.342147print(sqrt(abs(data$x))) # perform calculation on all values of "x"## [1] 1.19481086 0.80854443 1.47904226 1.29658513 0.60848155 1.42771391
## [7] 1.79930153 1.09241521 1.42558830 0.53340322 1.40016142 1.69394008
## [13] 0.97860927 2.16777605 2.03135177 2.09333800 2.53423085 0.65422687
## [19] 3.25073684 1.74218914 2.38767607 1.42193389 1.82815399 1.74569041
## [25] 3.13256907 1.84557877 1.65040419 1.19206627 1.44520275 1.39724837
## [31] 1.89997947 0.45311599 1.29670004 1.56386125 1.10886293 0.38715036
## [37] 1.99512205 1.15533545 0.68557946 1.15507662 0.63830016 1.06980185
## [43] 1.04564717 1.07821983 1.26939907 0.45258767 0.09628822 0.57048357
## [49] 0.99355971 0.48117336pairs(data) # create plots of each varialble vs. every other variable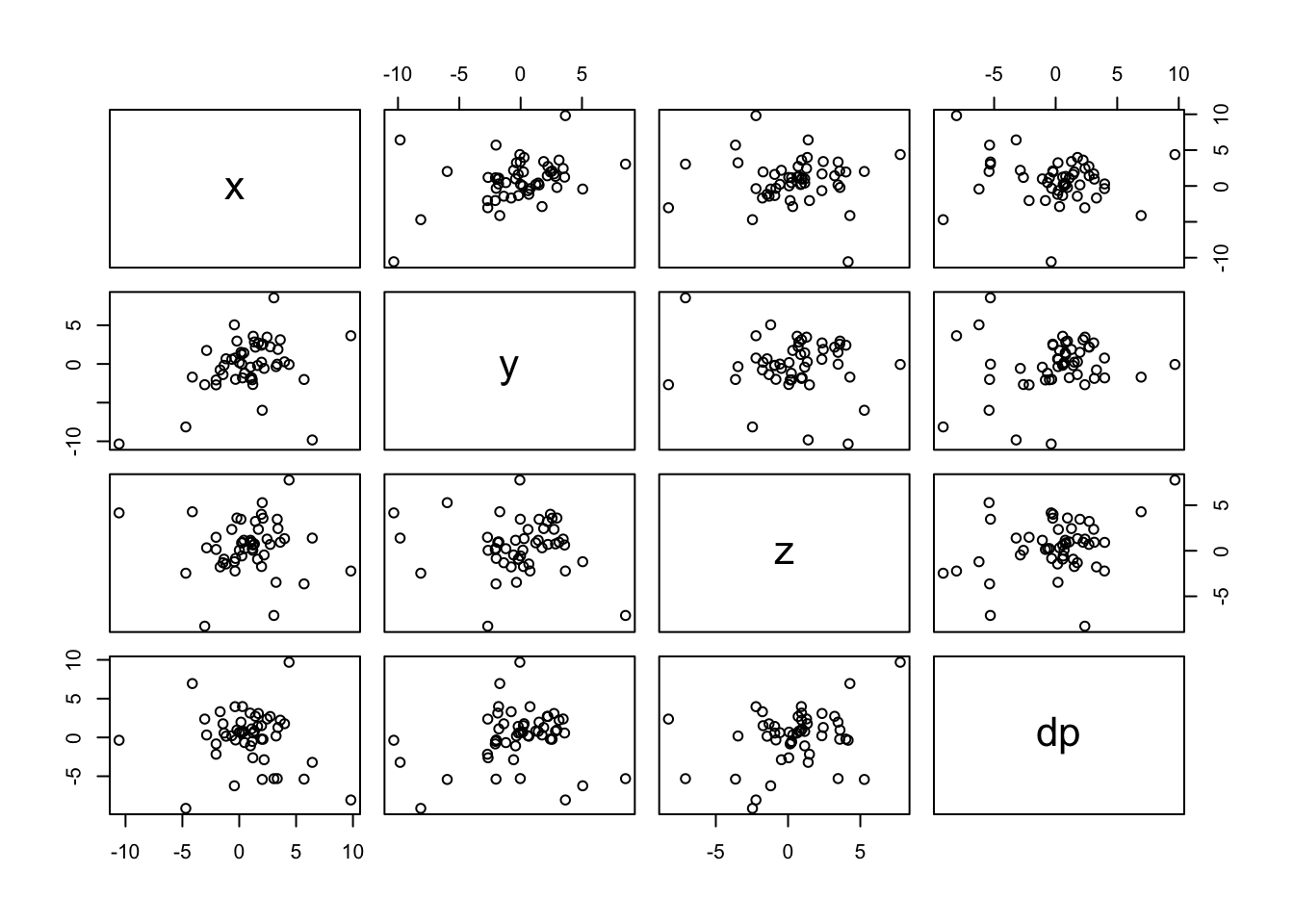
plot(data$x,data$dp) # plot one variable vs. another variable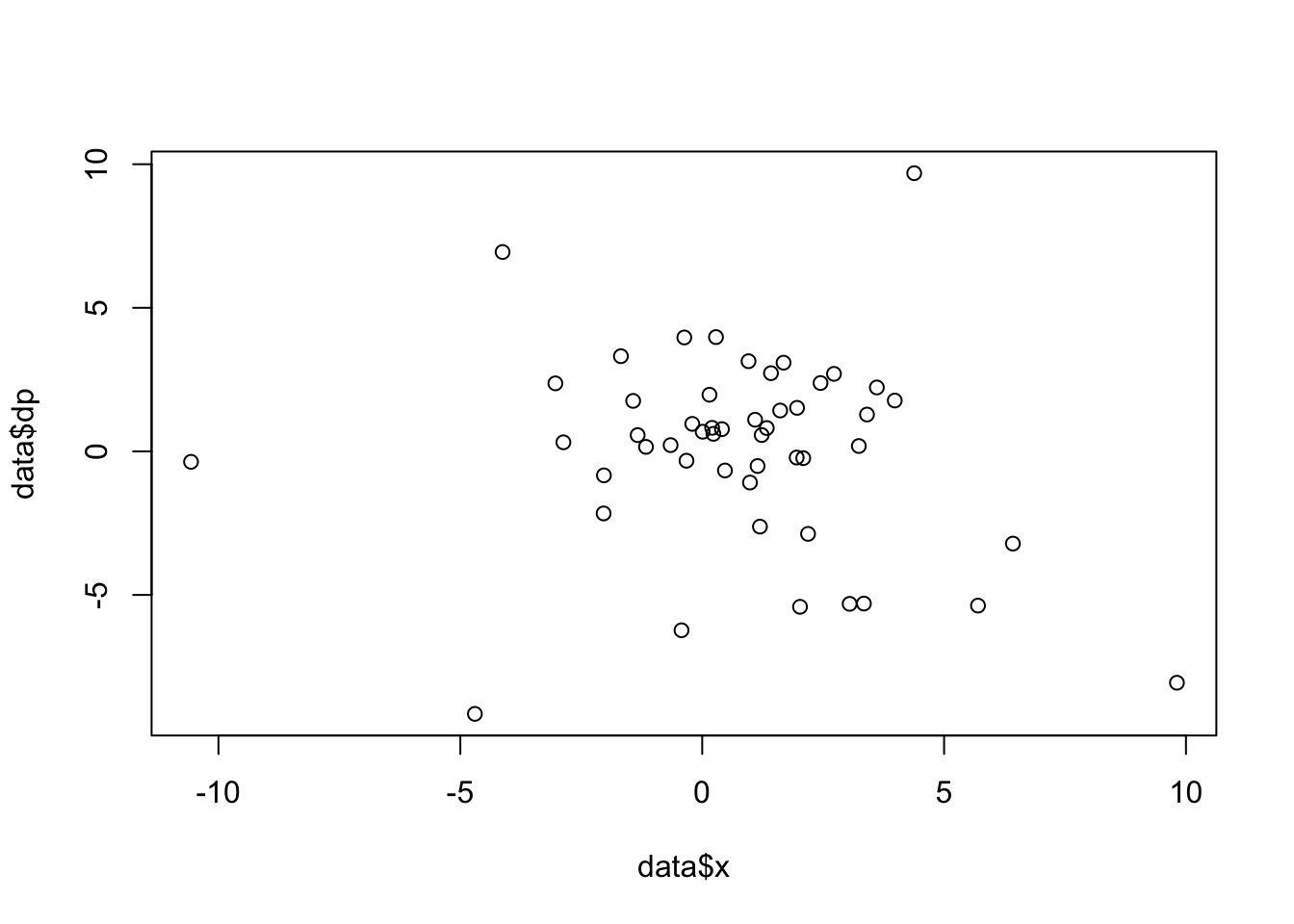
You can create a subsest of your dataset:
# find subset where abs(x)<0.8 AND abs(y)<1:
data_sub = subset(data, subset=( (abs(data$x)<4) & (abs(data$y)<1)) )
length(data_sub$x)## [1] 14plot(data_sub$x,data_sub$dp) # plot one variable vs. another variable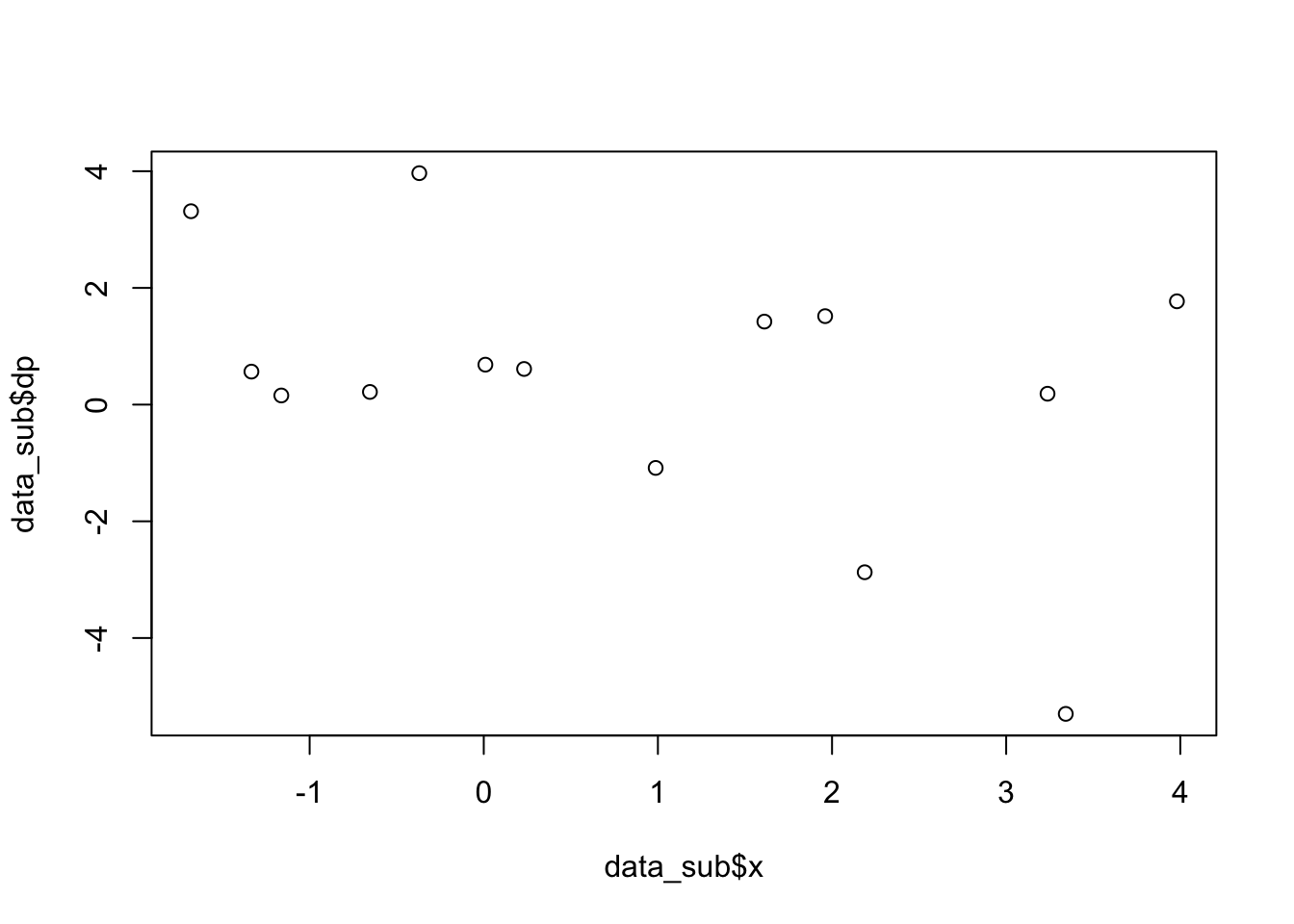
# note: a & b "a is true AND b is true" (intersection)
# a | b "a is true OR b is true" (union)
# !a "a is NOT true" (negation)
# other logical options: a< b a<=b a==b a>=b a!=b Next, we take our plot and fit the data to a linear model, finding the intercept and slope, and adding the corresponding line to the plot
fitparams = lm(dp ~ x, data_sub)
fitparams##
## Call:
## lm(formula = dp ~ x, data = data_sub)
##
## Coefficients:
## (Intercept) x
## 0.8473 -0.5435plot(data_sub$x,data_sub$dp)
abline(a=fitparams$coef[1], b=fitparams$coef[2],lty=2,col="red")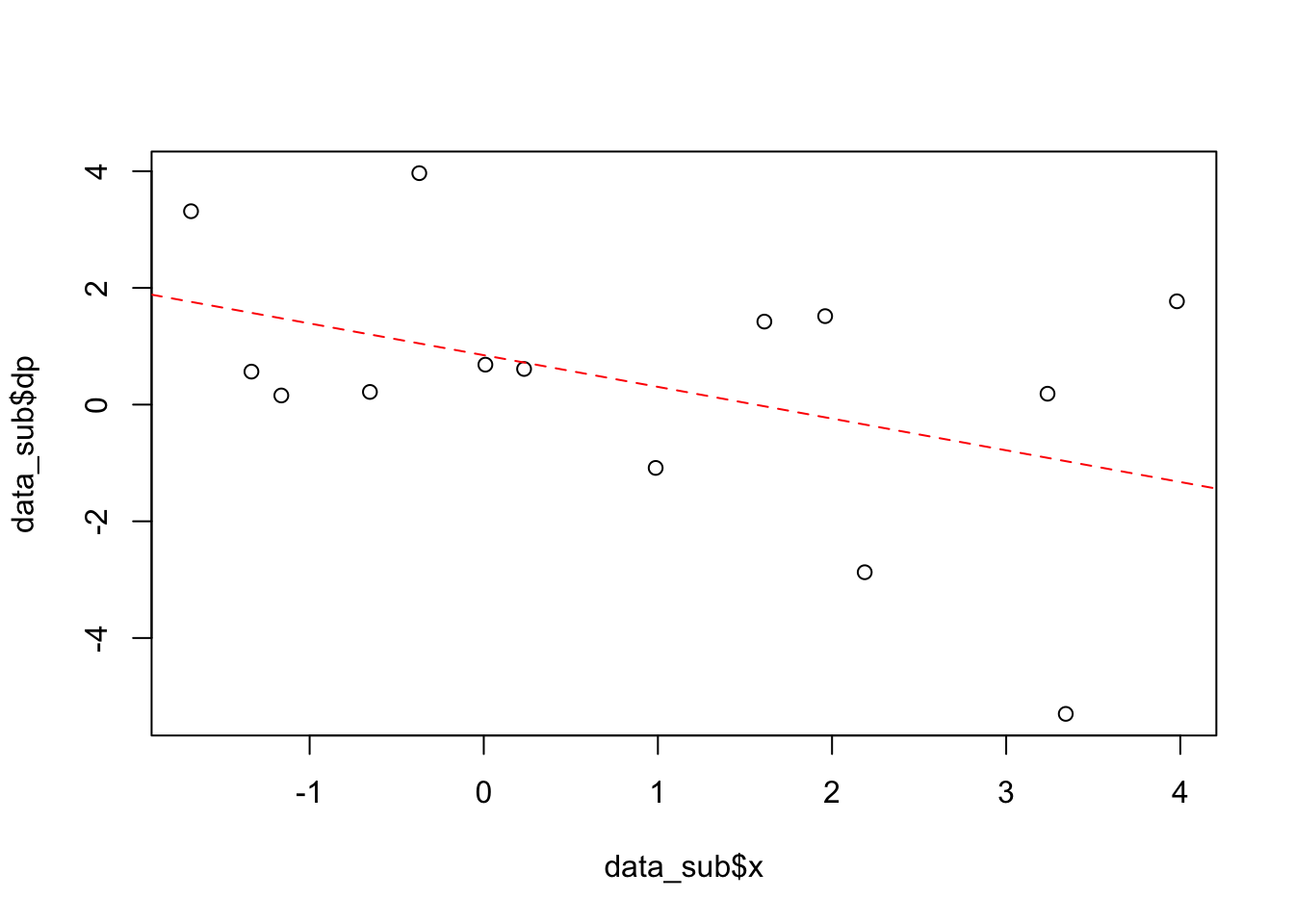
C.8 And Much, Much … Much, Much More
text manipulations; complex plotting control; optimizations; complex statistical analyses and modeling; …
visit: https://www.r-project.org/ for more information.
References
R Core Team. 2016. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. https://www.R-project.org/.